SQL 라이브 세션 강의
윈도우함수는 GROUP BY와 병행해서 사용할 수 없다.
- RANK
RANK() -> 1위 1위 3위
DENSE_RANK() ->1위 1위 2위
ROW_NUMBER() ->1위 2위 3위
- PERCENT_RANK
- 정의: 파티션별로 가장 먼저 나오는 값을 0, 가장 마지막에 나오는 값을 1로 정하여 행 순서별 백분율을 출력해줍니다. 구간을 나누어 백분율로 출력합니다.
- 문법: PERCENT_RANK() OVER (PARTITION BY 컬럼1 ORDER BY 컬럼2)
- 상위 N% 구할때 사용
- MATH 함수
| ABS | 절대값을 출력 | ABS(-1) | |
| ROUND | 숫자를 소수점 이하 자릿수에서 올림하여 출력. | ROUND(2.77,1) | |
| CEILING | 소수점을 올림하여 출력 | CEILING(2.77) | |
| FLOOR | 소수점을 내림하여 출력 | FLOOR(2.77) | |
| TRUNCATE | 숫자를 소수점 이하 자릿수에서 버림하여 출력 | TRUNCATE(2.77,1) | |
| RAND | 지정 숫자 범위 중 하나를 랜덤하게 출력 | ROUND(RAND()*100, 0) | 0~100 사이 랜덤값 |
- STRING 함수
| CONCAT | 문자열을 병합할 때 사용. | CONCAT(’피카츄’,’라이츄’) | 피카츄라이츄 |
| SUBSTRING | 문자열을 자를때 사용 | SUBSTRING(’피카츄라이츄’,2,4) | 카츄라 |
| SUBSTRING_INDEX | 문자열을특정 구분기호를 통해 출력할 때 사용 | SUBSTRING_INDEX(’피카.라이’, ’.’,1) | 피카 |
| REVERSE | 문자열을 뒤집을 때 사용 | REVERSE(’피카츄’) | 츄카피 |
- 날짜 함수
| NOW SYSDATE CURRENT_TIMESTAMP |
현재시간과 날짜를 출력 | NOW() SYSDATE() CURRENT_TIMESTAMP |
| DATE_ADD | 날짜에서 기준값 만큼 덧셈하여 출력 | DATE_ADD(’2024-04-03’, INTERVAL 1 DAY) |
| DATE_SUB | 날짜에서 기준값 만큼 뺄셈하여 출력 | DATE_SUB(’2024-04-03’, INTERVAL 1 DAY) |
| DATEDIFF | 두 날짜를 뺄셈하여 출력 | DATEDIFF('2024-04-03','2024-04-01') |
| DATE_FORMAT | 날짜를 형식에 맞게 출력 | DATE_FORMAT(now(),'%Y-%m-%d') |
| UNIX_TIMESTAMP |
현재시간을 UNIXTIME 으로 구함 | unix_timestamp() |
| CURDATE CURRENT_DATE |
현재 날짜 출력 | CURDATE() CURRENT_DATE() |
| CURTIME CURRENT_TIME |
현재 시간 출력 | CURTIME() CURRENT_TIME() |
| YEAR | 날짜의 연도 출력 | year('2024-04-01') |
| MONTH | 날짜의 월 출력 | month('2024-04-01') |
| DAY | 날짜의 일 출력 | day('2024-04-01') |
데이터 전처리 & 시각화 강의
1. 조건 넣고 출력하기
df[df[컬럼명]조건]]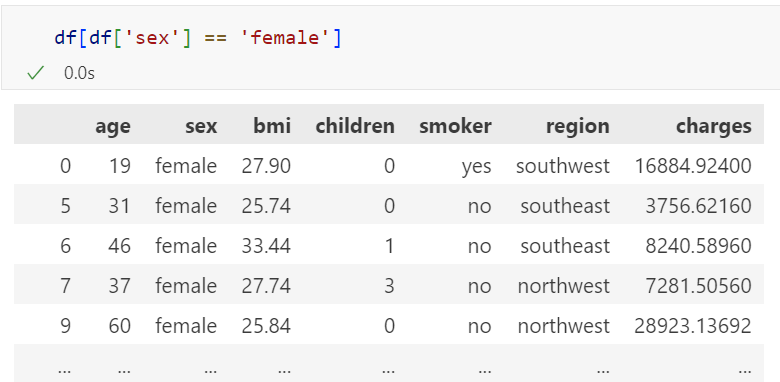
다중 조건
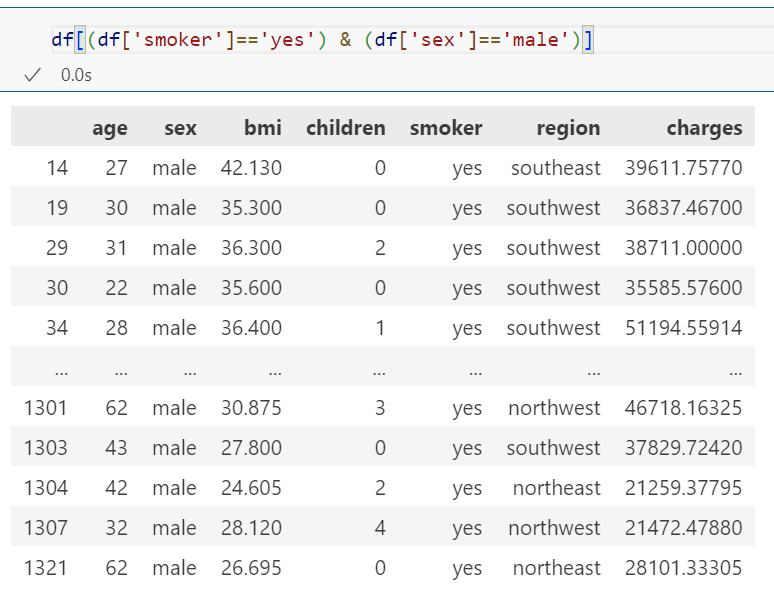
loc에도 조건 넣기 가능

isin() -> 조건 in
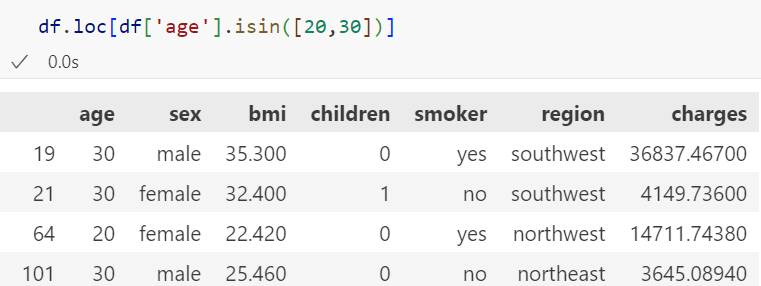
condition = df['컬럼명'] ='a'
df[condiion] #이것도 같은 결과나옴
\ 줄바꿈 코드, 조건 길어지면 \하고 엔터하고 더 쓰면 됨
| or 코드랑 헷갈리지 않기.
pd.to_datetime(df['컬럼명']) #date 타입으로 바뀜2. 병합하기
1. concat
- 컬럼이 같을 때

중복되면 중복 되는대로 나옴.
index까지 원래있던 순서대로 나오니까 pd.concat([a,b]).reset_index(drop = True) 해주면 인덱스 순서대로!
- 컬럼이 다를 때
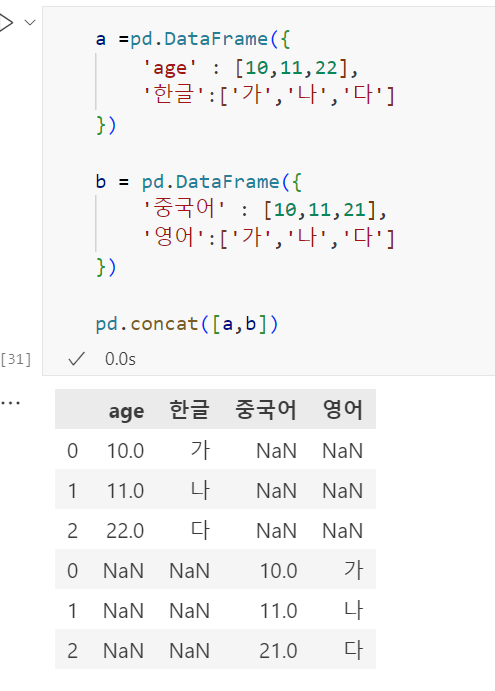
concat()함수는 기본이 axis = 0, 위아래로 합치기 때문에 컬럼 다르면 저렇게 나옴.
axis = 1로 해주면
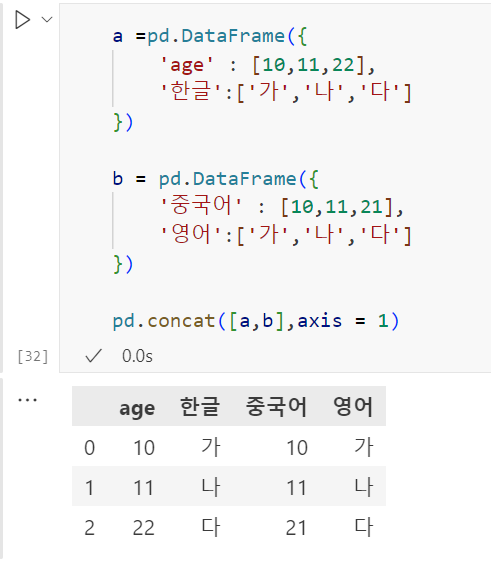
2. merge /sql join 과 같은 기능
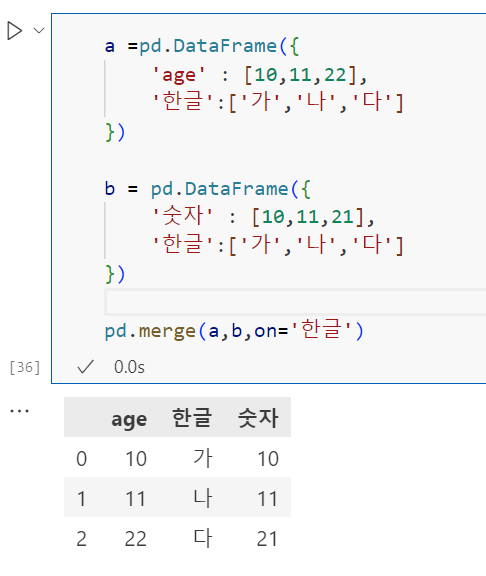
on 에 적힌 컬럼의 내용이 같을 경우에만 출력. how 안쓰면 inner join 같음

how에 left쓰면 leftjoin 과 같음.
3. 데이터 집계
groupby
a.groupby('한글').mean

sql처럼 컬럼에 대한 그룹별로 집계가 가능함.

agg(llist) 하면 그룹별로 배열로 값들이 출력됨.
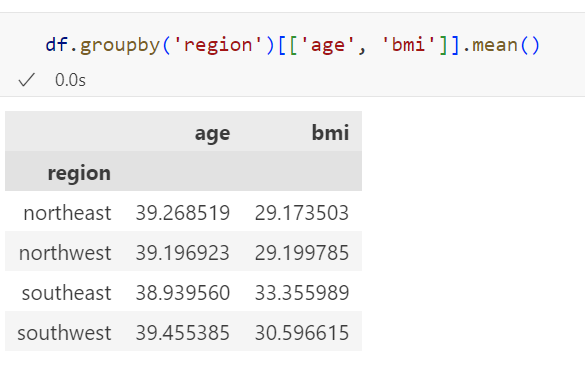
원하는 컬럼들만 계산하도록 하려면 저렇게 해주면 된다.

agg 사용하면 각 컬럼에 원하는 집계함수 사용 가능
4. pivot table
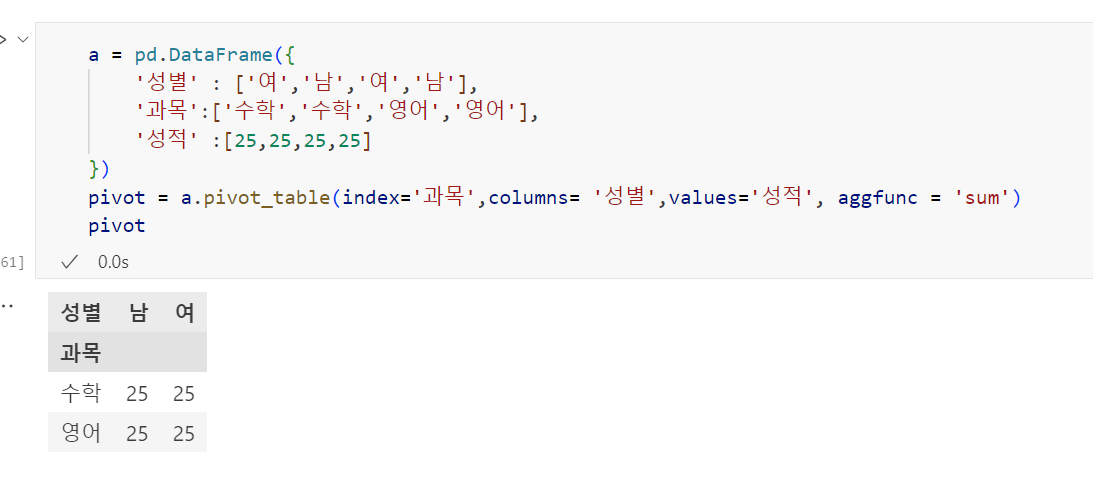
aggfunc = 'sum' 이거는 저기에 만약 수학 영어의 점수가 많을 때는 다 합해서 보여줌. mean 하면 평균 나옴
만약 컬럼 두 개면 배열[]로 묶어주면 됨
5. 정렬

sort_value(by = 컬럼명) order by같다.
ascending = False 해주면 내림차순 됨
두 개 기준으로 하고 싶으면 배열로 묶기
sort_index()하면 인덱스 순으로 정렬
오늘 한 일
sql 코드카타 5개
python 코드카타 5개
sql 라이브세션 수강
데이터 전처리 시각화 3주차 완강
'데이터분석 6기 > 본캠프' 카테고리의 다른 글
| [WIL] 3주차 회고 (0) | 2025.03.10 |
|---|---|
| [TIL] 2025-03-07 파이썬 순열, 집합 ,any ,all (0) | 2025.03.07 |
| [TIL] 2025-03-05 데이터 전처리 & 시각화 강의 (0) | 2025.03.05 |
| [WIL] 데이터 분석 캠프 2주차 회고 (0) | 2025.03.04 |
| [TIL]2025-03-04 데이터 리터러시 강의 (1) | 2025.03.04 |