무신사 사이트
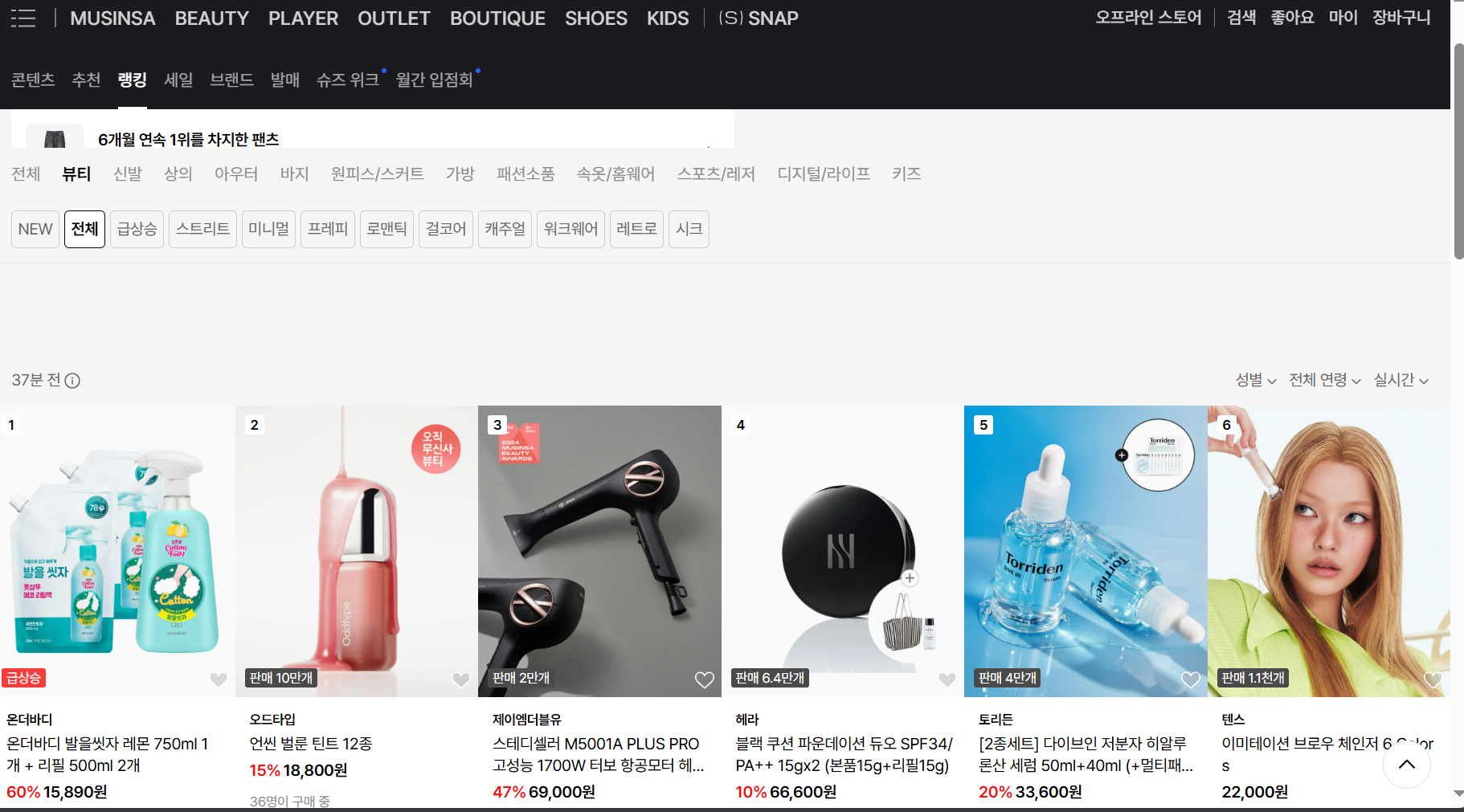
무신사는 각 카테고리별로, 세부 카테고리별로 랭킹이 300개씩 있다.
나와있는 모든 랭킹을 크롤링 하는 것을 목표로 하고 크롤링을 시작했다.
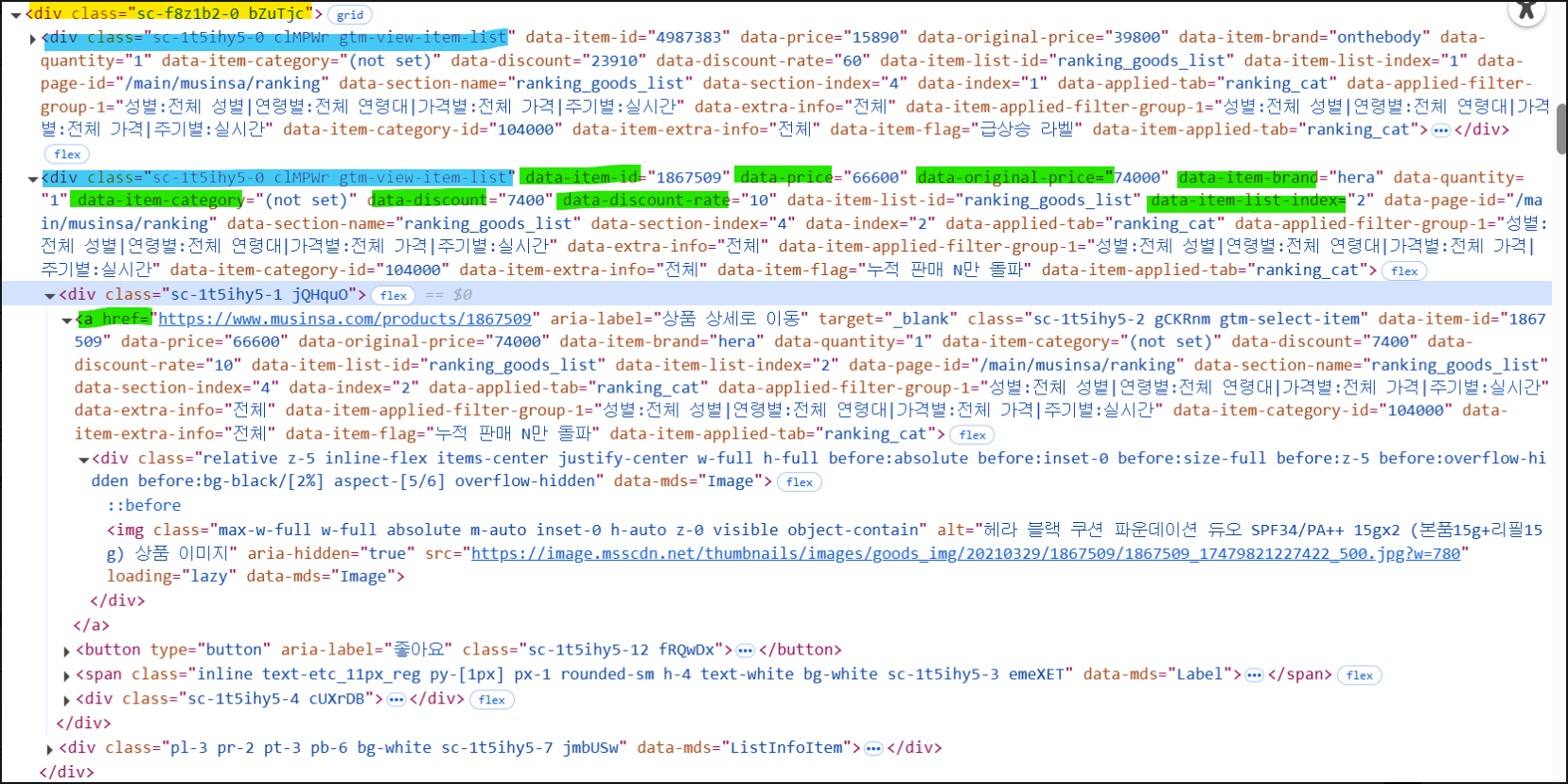
저 목록을 보면 구조가 이런식으로 돼있다.
노란색이 전체 제품 구조이고, 파란색으로 칠한 개 하나하나의 제품이 들어있다.
정적 크롤링 시도
base_url = 'https://www.musinsa.com'
url = "https://www.musinsa.com/main/musinsa/ranking?storeCode=musinsa§ionId=199&contentsId=&categoryCode=104000"
headers = {
'User-Agent': 'Mozilla/5.0'
}
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'html.parser')
data = []
items = soup.select('div.sc-1t5ihy5-0.clMPWr.gtm-view-item-list') # 정확한 클래스 선택
for item in items:
a_tag = item.select_one('a[href*="/products/"]')
if not a_tag:
continue
product_url = base_url + a_tag['href']
product_id = a_tag.get('data-item-id')
brand = a_tag.get('data-item-brand')
price = a_tag.get('data-price')
original_price = a_tag.get('data-original-price')
discount_rate = a_tag.get('data-discount-rate')
img_tag = a_tag.select_one('img')
product_name = img_tag['alt'].strip() if img_tag and 'alt' in img_tag.attrs else None
data.append({
'상세주소': product_url,
'상품 ID': product_id,
'브랜드': brand,
'제품명': product_name,
'정가': original_price,
'할인가': price,
'할인율': discount_rate
})
# 확인용 출력
for d in data:
print(d)처음에는 이런식으로 정적 크롤링에 접근했는데, 보안상 이유인지 계속 아무 데이터도 들어오지 않았다.
그래서 결국 동적 크롤링으로 바꾸었다.
동적 크롤링 시도
from selenium import webdriver
from bs4 import BeautifulSoup
import time
# 셀레니움 웹드라이버 실행
driver = webdriver.Chrome()
driver.get("https://www.musinsa.com/main/musinsa/ranking?storeCode=musinsa§ionId=199&contentsId=&categoryCode=104000")
time.sleep(3) # JS 로딩 시간
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
driver.quit()
# 기존 방식대로 크롤링
items = soup.select('div.gtm-view-item-list')
print(f"상품 개수: {len(items)}개")
for item in items:
a_tag = item.select_one('a[href*="/products/"]')
if not a_tag:
continue
product_url = "https://www.musinsa.com" + a_tag['href']
product_id = item.get('data-item-id')
brand = item.get('data-item-brand')
price = item.get('data-price')
original_price = item.get('data-original-price')
discount_rate = item.get('data-discount-rate')
img_tag = a_tag.select_one('img')
product_name = img_tag['alt'].strip() if img_tag and 'alt' in img_tag.attrs else None
print({
'상세주소': product_url,
'상품 ID': product_id,
'브랜드': brand,
'제품명': product_name,
'정가': original_price,
'할인가': price,
'할인율': discount_rate
})
클래스 안에 다른 태그 없이 그냥 data-item-id="4085614" 이런식으로 쭉쭉 써져있다면 .get() 함수를 사용하면 된다.
더 추가할 것
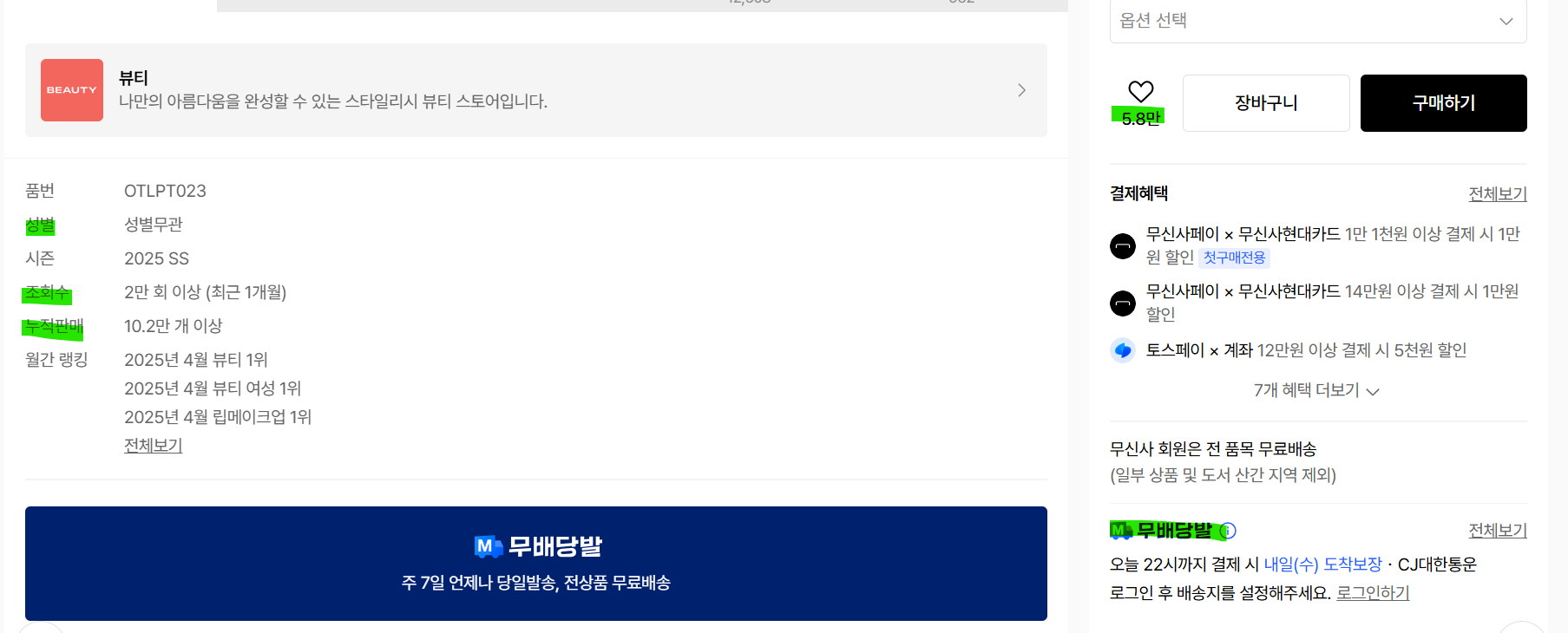
이제 상세페이지에 가면 성별, 조회수, 누적 판매, 찜 수. 무배당발 여부를 알 수 있다.
이것들을 추가로 크롤링 해야한다.

후기 평점과 개수, 카테고리도 함께 가져오려고 한다.
성별, 누적판매, 조회수

구조는 이런식으로 dl sc-2ll6b5-0.doA-dRN 안에 있는 dt 태그에 구분, 그리고 dd에 그 사항이 나와있는 형식이었다.
def parse_detail_page(url):
# 셀레니움 크롬 드라이버 실행
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 창 안 띄우기
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome(options=options)
driver.get(url)
time.sleep(3) # JS 로딩 시간
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()
#성별, 조회수, 누적판매
info = {
'성별': None,
'조회수': None,
'누적판매': None
}
dt_tags = soup.select('dl.sc-2ll6b5-0.doA-dRN dt')
for dt in dt_tags:
label = dt.get_text(strip=True).replace(':', '')
dd = dt.find_next_sibling('dd')
value = dd.get_text(strip=True) if dd else None
if label == '성별':
info['성별'] = value
elif label == '조회수':
info['조회수'] = value
elif label == '누적판매':
info['누적판매'] = value이 페이지도 마찬가지로 동적으로밖에 안돼서 동적 크롤링을 진행했다.
우선 dt를 선택해준 다음, 그 안에서 dd를 찾아서 둘을 저장하는 식으로 진행했다.
대분류, 중분류, 소분류

이 코드를 보면 a 태그 안에 data-category-id = 1depth 부터 3depth 인 거 까지 있고, 각 분류는 data-category-name으로 지정돼있다.
# 대분류~소분류까지 전부 검색 후 info에 저장
category_tags = soup.select('a[data-category-name]')
for tag in category_tags:
cid = tag.get('data-category-id')
cname = tag.get('data-category-name')
if cid == '1depth':
info['대분류'] = cname
elif cid == '2depth':
info['중분류'] = cname
elif cid == '3depth':
info['소분류'] = cname그래서 parse_detail_page 함수에 이런식으로 저장했다.

이렇게 저장 완료!!!
내일 이어서 찜 수를 해봐야겠다~~!
'데이터분석 6기 > 본캠프' 카테고리의 다른 글
| 2025-05-29 최종 프로젝트 데이터 살펴보기 (0) | 2025.05.29 |
|---|---|
| 2025-05-28 spark 피하기 (0) | 2025.05.28 |
| 2025-05-27 스파크 특강 ot (1) | 2025.05.27 |
| 2025-05-26 spark (1) | 2025.05.26 |
| 2025-05-24 정적 크롤링 과제 (0) | 2025.05.24 |